
Architecture Matters
Yes, architecture matters immensely. Many applications use the traditional layered architecture which is shown here:
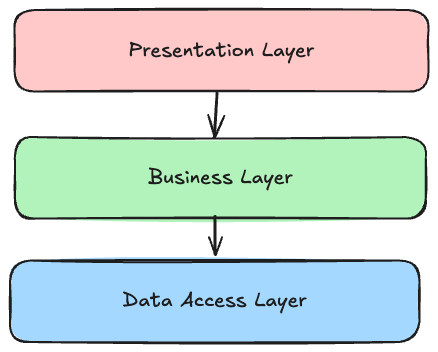
The Presentation Layer contains the controllers, e.g. REST controllers. The Business Layer contains the business logic
within services. The Data Access Layer is responsible for accessing the database. Not the dependencies. The Business
Layer depends on the Data Access Layer. The Presentation Layer depends on the Business Layer and transitively depends
on the Data Access Layer.
In my opinion, this layered architecture is fine if we are talking about a small application. By small, I mean an application that
can be rebuilt from scratch in a small amount of time, say no more than a few months (preferably not more than one month
in my opinion).
For larger applications, it becomes problematic. Every large application I have worked on that has used this architecture
has become a Big Ball of Mud. There are plenty of reasons why this happens from layers bleeding into each other, a lack of boundaries, a lack of encapsulation,
tightly coupled services, etc.
We have better options for building our applications. The following are some of the architectural pattens we can
use to build our applications. And we can actually combine these architectural patterns together in the same application.
- Modular Monoliths (Moduliths)
- Hexagonal/Clean/Onion Architectures
- Vertical Slice Architecture
- Event-Driven Architecture (EDA)
- Command Query Responsibility Segregation (CQRS)
- Domain-Driven Design (DDD)
Modular Monoliths (Moduliths)
Derek Comartin has a great
video/article
on what he calls a loosely coupled monolith. In my opinion, it's the same thing as a modular monolith.
Be sure to also check his video START with a Monolith, NOT Microservices.
Hexagonal/Clean/Onion Architectures
The D in the SOLID Princples
is Dependency Inversion. It is the cornerstone for the Hexagonal, Clean, and Onion Architectures.
Please watch Hexagonal, Onion & Clean Architecture for
a short introduction covering these architectures. In particular, pay close attention to the start of the video which
explains dependency inversion.
Before we go any further, we need to stop and make sure we really understand dependency inversion. I'm assuming you
have watched the previously mentioned video. At about the 0:39 mark, the presentation introduces the IRepository interface
in the Business Logic layer. From the video, it looks like the IRepository interface is simply moved from the
Data Access layer to the Business Logic layer. There's actually more to the story. It's actually a completely
different interface.
To fully understand this, let's use an example. Let's suppose we are using the traditional layered architecture.
In our example we simply want our Business Logic layer to retrieve an employee from the database. Using Java and
JPA, our EmployeeEntity might resemble:
@Entity
@Table(name = "employees")
public class EmployeeEntity {
@Id
@GeneratedValue(strategy = GenerationType.UUID)
private UUID id;
private String firstName;
private String lastName;
// ... other properties
}
In a typical layered architecture, our repository interface would look like this:
public interface EmployeeRepository {
Optional<EmployeeEntity> findById(UUID id);
}
The key thing to note is that the interface is returning the JPA entity. When the Business Logic layer uses
this interface, the EmployeeEntity will be bleeding into the business logic. That makes the business logic
tightly coupled to how the data is stored in the database.
With dependency inversion, the Data Access layer still has the same EmployeeEntity, but the Business Logic layer
cannot use it because it no longer depends on the Data Access layer. Rather, the Business Logic Layer creates
its own representation of an Employee, e.g.
public class Employee {
private UUID id;
private String firstName;
private String lastName;
// ... other properties, constructor, and methods
}
Most importantly, the Business Logic layer defines the interface as such:
public interface EmployeeRepository {
Optional<Employee> findById(UUID id);
}
Using dependency inversion, the Data Access layer now depends on the Business Logic layer, not the other way around.
Because of this, the Data Access layer must now implement the Business Logic layer's EmployeeRepository. The Data
Access layer can still use its EmployeeEntity, but it must then map it to the Employee needed by the Business Logic layer.
Lastly, via the magic of dependency injection (not inversion), the actual implementation from the Data Access layer
can be injected into any of the Business Logic layer services that need it.
Now let's return to our architectures.
Hexagonal (also known as Ports and Adapters) was designed by Alistair Cockburn in the mid 1990s but was officially
introduced in 2005. Take a look his original paper on The Hexagonal (Ports & Adapters) Architecture.
For a simple explanation of Hexagonal, check out
Ports & Adapters Architecture.
Another good article on Hexagonal is
Hexagonal Architecture - System Design.
Next up is the Onion Architecture by Jeffery Palermo which was introduced in 2008. He has a three part series on the architecture. Obviously, I
recommend starting with
The Onion Architecture: part 1.
Lastly, we have the Clean Architecture by Robert C. Martin (aka Uncle Bob) which was introduced in 2012. It has much in common
with the Onion Architecture. I recommend starting with his
blog
that describes the architecture. If you prefer to watch a video, check out
Clean Architecture Explained: The Dependency Rule & Why It Matters.
The differences between Onion and Clean are subtle and the differences in terminology can make it confusing. If you are not
yet sure of the differences, please check out
Onion Architecture vs Clean Architecture Comparison.
Lastly, which one is the best? Or which one should you choose? Answer: it doesn't matter. For a complete
discussion on why, please check out
Hexagonal vs Clean vs Onion Architecture... It Doesn't Matter.
Vertical Slice Architecture
In 2018, Jimmy Bogard wrote a blog entry titled Vertical Slice Architecture.
The Hexagonal, Clean, and Onion architectures really focus on loose coupling and separating concerns, e.g. the business code is
not cluttered with database concerns. Vertical Slices focuses on cohesion. Things that go together, stay together.
The code to add a new employee record doesn't have to be spread out across distant folders. We can put the code
together in one folder. That's a slice. We can, though, continue to use the Hexagonal, Clean, and Onion architectures
within that slice/folder to enforce loose coupling. Please watch
Tired of Layers? Vertical
Slice Architecture to the rescue! for a great
discussion and some sample code on Vertical Slices. Another great video is
Vertical Slice Architecture Myths You Need To Know!.
Event-Driven Architecture (EDA)
In What do you mean by “Event-Driven”?,
Martin Fowler identifies three different patterns:
- Event Notification
- Event-Carried State Transfer
- Event-Sourcing
Since Event-Sourcing is a complex topic in itself, I'll be excluding it from this discussion. The other two, though,
are closely related. Let's start with Event Notification. Let's say we have a customer relationship management (CRM)
application and a separate billing application that also maintains a copy of the customer's information. Whenever
the customer's address changes in the CRM, an event is published. That event might be called customerAddressChanged,
and it includes the customer's ID. The billing application is listening for that event. When it receives it,
the billing application uses the customer's ID to make a call back to the CRM to obtain the new address which it then stores in its
database.
The Event-Carried State Transfer takes a different approach. When the CRM publishes the customerAddressChanged
event it does include the customer's ID, but it also includes the new address. That state change is included in the
event. By doing that, the billing application doesn't need to make a call back to the CRM. It can simply update its
database with the new address for that customer.
So, which one is better? Neither. Both have their advantages and disadvantages. Event Notification is more lightweight
but can be a problem when calling back to the source, e.g. the billing application makes a call to the CRM to get
the customer's address, but the CRM is currently offline. Event-Carried State Transfer has a much larger payload
that must be understood by the event listeners. Also, the data could be stale. If there are two address changes to the
same customer in succession, logic must exist to use the latest address. Please read
Event Notification vs. Event-Carried State Transfer
for an excellent discussion of these issues.
For a brief but excellent overview of Event-Driven Architecture, check out
Event Driven Architecture EXPLAINED in 15 Minutes.
Command Query Responsibility Segregation (CQRS)
Commands are any operation that modifies state, e.g. causes changes to what is stored in the database. Queries
return data but never change the state. As for implementing it, there isn't just one approach.
One approach is to use the same database for both commands and queries. It may be, though, that the data model is
optimized for writes but not optimized for reads. In that case, materialized views can be created which will
significantly improve query performance.
Another approach is to have separate databases with different data models. The database for commands is optimized for writes and the database
for queries is optimized for reads. The query databases, though, must be kept in sync with the command database
as changes are made.
💡
Some people may confuse CQRS with Command Query Separation (CQS) which was introduced by Bertrand Meyer.
CQS states that every function either alters the state (a command) or performs a query, never both. CQRS, though, works
at the application level, not at the function level.
If you would like an excellent visual explanation, check out
CQS and CQRS: Command Query Responsibility Separation.
If you want to learn more, check out Martin Fowler's article on CQRS.
Domain-Driven Design (DDD)
Domain-Driven Design (DDD) was introduced by Eric Evans in 2003 in his classic book Domain-Driven Design: Tackling Complexity in the Heart of Software.
DDD is a huge topic and I will not be attempting to cover all of it. Our focus will be on aggregate roots. Let's start with
some terminology:
- Entity: a domain object with a unique identifier, e.g. a UUID.
- Value Object: an immutable object that does not have an identifier. An example may be the address of an employee. The employee is an entity with an id, but the address not have an id. If the address needs to change, the entire address is replaced.
- Aggregate: a group of related entities and value objects.
- Aggregate Root: the single entity within an aggregate which controls all changes to the aggregate. For example, if we have an Order with a set of Line Items, the Line Items can only be changed by going through the Aggregate Root which is the Order.
The following are the qualities of a well-designed aggregate:
- Small: When we need to modify an aggregate, we need to read the entire aggregate from the datastore. We then make the necessary changes and write the entire aggregate back to the datastore within one transaction. If your aggregate is a Company and all 1000 Employees, performance will be a major problem. Keep aggregates small.
- Enforce Invariants: Aggregates must be valid at all times. They are not allowed to go into an invalid state. For example, if an order has already been delivered, a customer can't cancel the order.
- References: Aggregates do reference other aggregates, but should only do so via the aggregate's root id. For example, an Employee belongs to a Company, but it should only have the ID of the Company, not a reference to the Company's instance.
To learn more about best practices for aggregates, please read
DDD Modelling - Aggregates vs Entities: A Practical Guide
or watch CodeOpinion's
What makes an Aggregate (DDD)? Hint: it's NOT hierarchy & relationships.
©
Donald A. Barre. All rights reserved.